Olá,
À medida que o mundo da tecnologia da informação continua a evoluir, novas funções e especializações surgem para atender às demandas complexas do gerenciamento de dados. Três papéis cruciais que frequentemente geram confusão são os de Database Reliability Engineer (DBRE), Database Administrator (DBA) e Cientista de Dados. Vamos explorar suas diferenças e compreender como esses profissionais contribuem para o ecossistema de dados.

Database Reliability Engineer (DBRE): A Ponte Entre Desenvolvimento e Operações
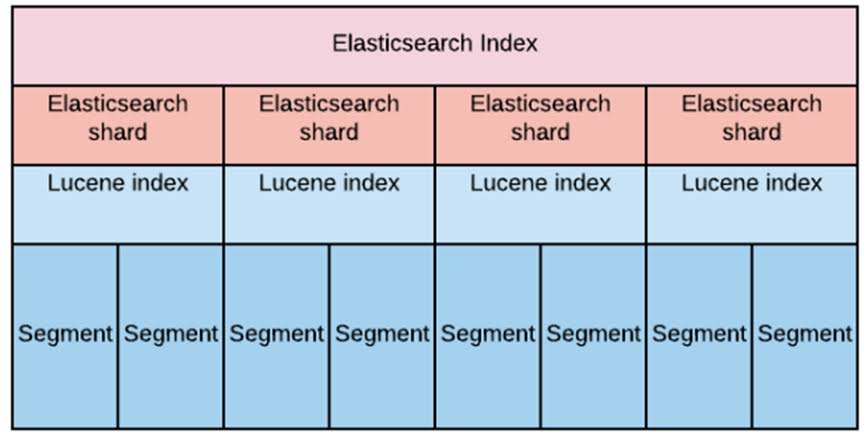
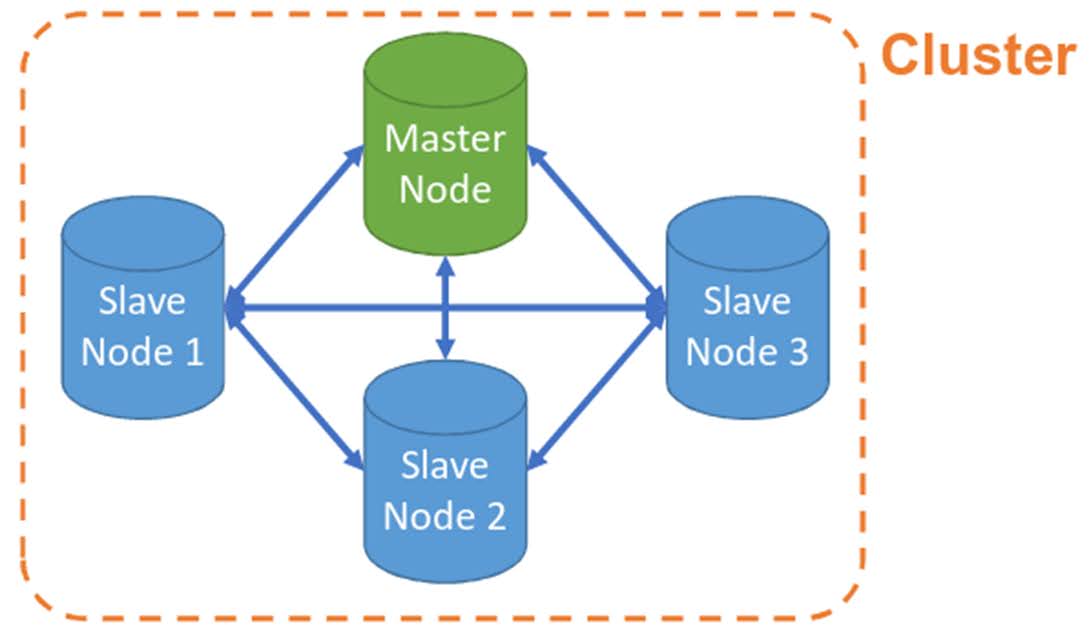
O DBRE é um profissional que se concentra na confiabilidade e eficiência dos bancos de dados. Sua função é garantir que os sistemas de gerenciamento de banco de dados (DBMS) estejam sempre disponíveis, resilientes e otimizados. Eles atuam como uma ponte entre desenvolvedores e equipes de operações, garantindo que as aplicações se integrem harmoniosamente aos bancos de dados sejam eles banco de dados relacionais ou NOSQL.
Principais responsabilidades do DBRE:
- Garantir Alta Disponibilidade: Os DBREs trabalham para minimizar o tempo de inatividade do sistema, implementando estratégias como replicação de dados e failover automático.
- Desempenho Otimizado: Monitoram o desempenho do banco de dados, identificando gargalos e otimizando consultas para melhorar a eficiência.
- Automação e Escalonamento: Automatizam tarefas repetitivas e garantem que os bancos de dados possam lidar com cargas crescentes de dados sem comprometer a performance.
Database Administrator (DBA): Guardião dos Dados e Estruturas do Banco de Dados
Enquanto o DBRE se concentra na confiabilidade, o DBA é o guardião dos dados e da estrutura do banco de dados. Eles desempenham um papel vital na criação, manutenção e otimização de esquemas de banco de dados, garantindo a integridade e segurança dos dados armazenados.
Principais responsabilidades do DBA:
- Design de Banco de Dados: Planejam e implementam a estrutura do banco de dados, considerando requisitos de desempenho, escalabilidade e segurança.
- Segurança e Integridade: Implementam políticas de segurança, controle de acesso e garantem a integridade dos dados por meio de backups e recuperação.
- Manutenção e Otimização: Realizam tarefas de manutenção, como índices de reorganização e estatísticas de atualização para otimizar o desempenho do banco de dados.
Cientista de Dados: Transformando Dados em Insights Estratégicos
Os Cientistas de Dados são responsáveis por extrair insights valiosos a partir de conjuntos de dados. Envolvem-se em análise estatística, machine learning e modelagem preditiva para ajudar as organizações a tomar decisões informadas.
Principais responsabilidades do Cientista de Dados:
- Análise Exploratória de Dados: Exploram grandes conjuntos de dados para identificar padrões, tendências e relações que podem ser usados para tomada de decisões.
- Desenvolvimento de Modelos Preditivos: Utilizam algoritmos de machine learning para criar modelos que preveem comportamentos futuros com base em dados históricos.
- Comunicação de Resultados: Traduzem resultados complexos em insights compreensíveis, facilitando a tomada de decisões por parte da equipe de gestão.
Em resumo, enquanto o DBRE e o DBA garantem a integridade, confiabilidade e eficiência dos bancos de dados, o Cientista de Dados utiliza esses dados para gerar valor estratégico. Juntos, esses profissionais formam uma equipe essencial para o gerenciamento eficaz de dados em um ambiente tecnológico em constante evolução.